인덱스 ( Indexes ) 란? & 인덱스는 꼭 필요한 것인가?
인덱스는 쿼리가 수행되면서 찾는 데이터의 위치를 알려주는 역할을 한다.
빠른 검색을 위한 인덱스는 데이터가 많은 테이블에서 필요하다.
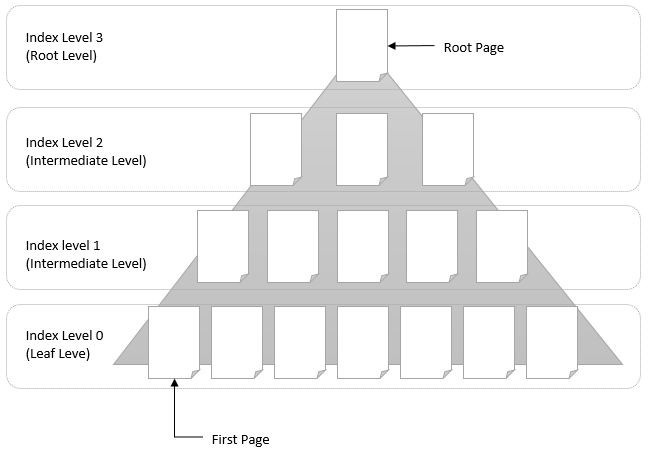
인덱스의 구조
인덱스는 루트레벨, 리프 레벨, 인터미티어트 레벨로 구성되어 있으며, 루트 레벨은 루트 페이지 즉 인덱스 페이지의 최상의 수준을 말한다. 리프 레벨은 리프 페이지, 퍼스트 페이지라고 불리며 인덱스 페이지의 최하위 수준을 말한다. 인터미디어트 레벨은 최상위 수준과 최하위 수준 사이를 말한다.
테이블 ( Heaps VS Clustered Indexes)
힙(Heaps) 테이블
데이터 페이지와 페이지 안의 데이터가 순서없이 존재하는 테이블로 INSERT 문에 좋다. 테이블 스캔 시에 테이블 전체를 조회하고 쿼리문의 성능이 떨어진다.

클러스터형 인덱스 (Clustered Indexes)
정렬된 형태의 데이터를 가지고 있으며 이게 곧 테이블이다. 정렬된 열이 아닌 다른 열로 검색할 경우 전체를 스캔한다.

힙 + 비클러스터형 인덱스
힙형태의 테이블에 비클러스터형 인덱스를 만들경우 아래와 같은 과정으로 인덱스가 구성된다.
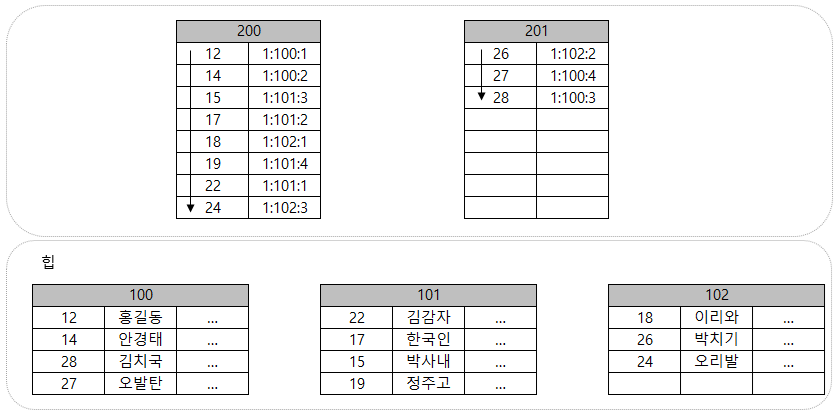
별도의 공간에 인덱스 정보를 저장하는데 이를 인덱스 페이지라고 부른다. 데이터 행의 주소(RID)를 인덱스 페이지에 같이 저장한다.
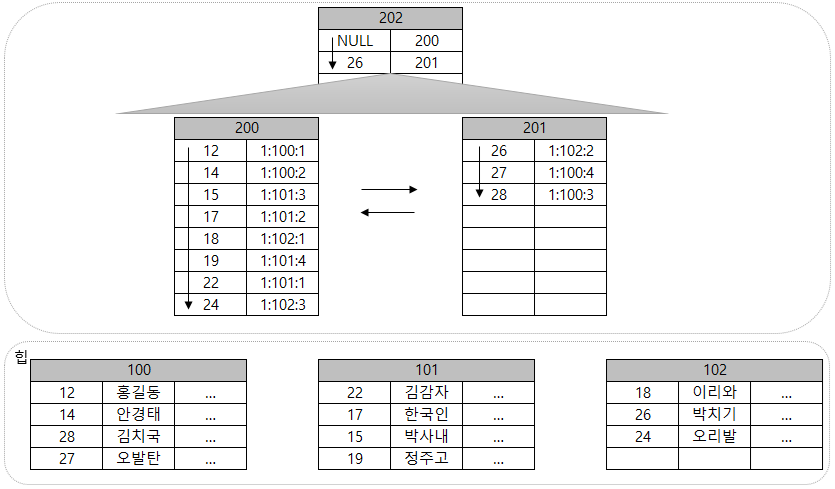
200번 페이지와 201번 페이지로 분기할 수 있는 정보가 포함된 Root 페이지 202번 페이지를 만든다.
이렇게 구성된 인덱스에서 15번 고객의 데이터 행을 찾는 과정은 아래와 같다.
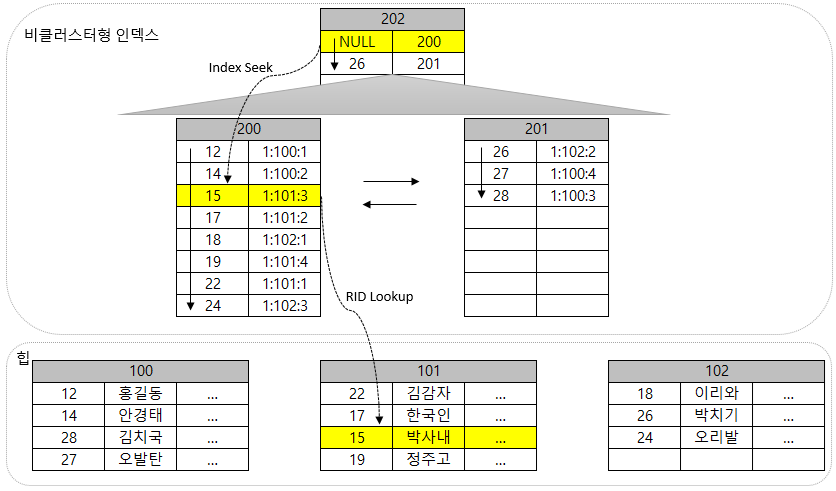
이 상황에서 "16 어쩌구" 데이터를 추가한다고 가정해보도록 한다.
200번 페이지가 공간이 부족하기 때문에 200번 페이지를 나누어 203번 페이지에 할당한다. 그리고 Root 페이지인 202번 페이지에는 추가된 페이지의 정보를 등록한다.
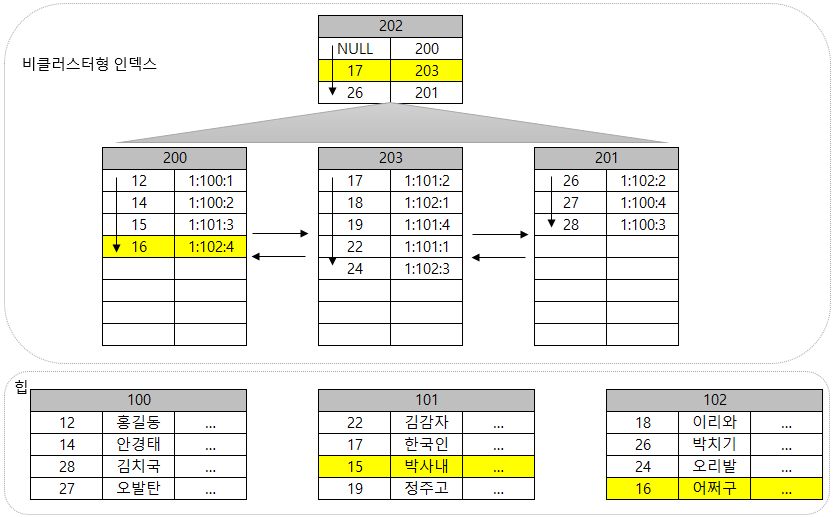
이렇게 데이터가 INSERT됨에 따라 페이지가 나뉘지는 것을 페이지 분할(Page Split)라고 부른다. 이 과정이 많아지면 성능에 저하가 발생한다. 그래서 인덱스에 데이터를 얼마나 채울지(Fill Factor)를 정하고 그것을 관리하기도 한다.
클러스터형 인덱스
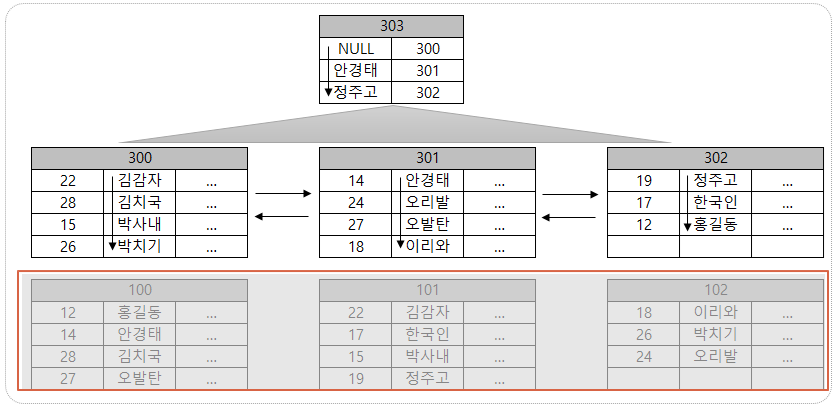
힙테이블에서 클러스터형 인덱스를 만들 경우 위의 빨강색 테두리 형식에서 위의 형식으로 변환되게 된다. 클러스터형 인덱스를 "이름" 컬럼으로 만든 예이다.
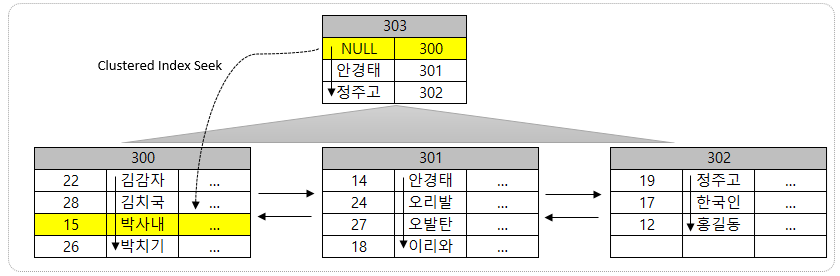
이렇게 구성된 클러스터형 인덱스에서 "15 박사내"를 찾는다면 303 페이지 즉, Root 페이지에서 이름으로 찾은 후 "NULL" 과 "안경태" 사이이므로 300페이지로 가서 "박사내"를 찾을 것이다.
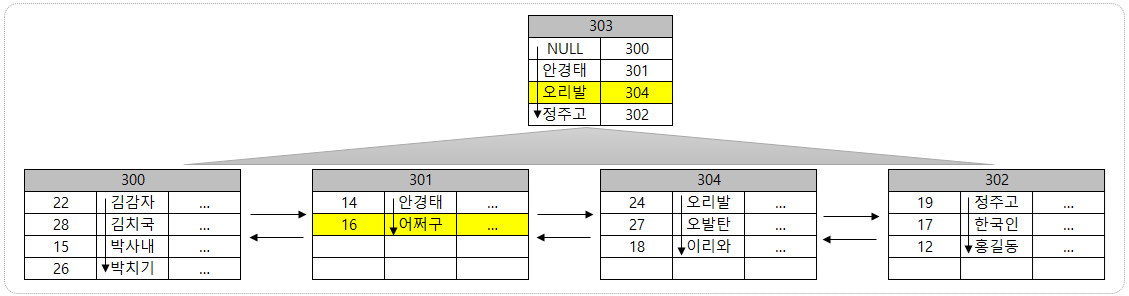
데이터 "16 어쩌구"를 추가한다면 기존 301 페이지에 들어갈 공간이 없기 때문에 304 페이지를 만들고 301페이지와 304페이지에 데이터를 분할 한 후 "16 어쩌구"를 넣는다. 그리고 Root 페이지인 303페이지에 추가된 페이지 정보를 넣는다.
클러스터형 인덱스 + 비클러스터형 인덱스
가장 일반적인 구조인 클러스터형과 비클러스터형 인덱스가 혼합된 경우이다.
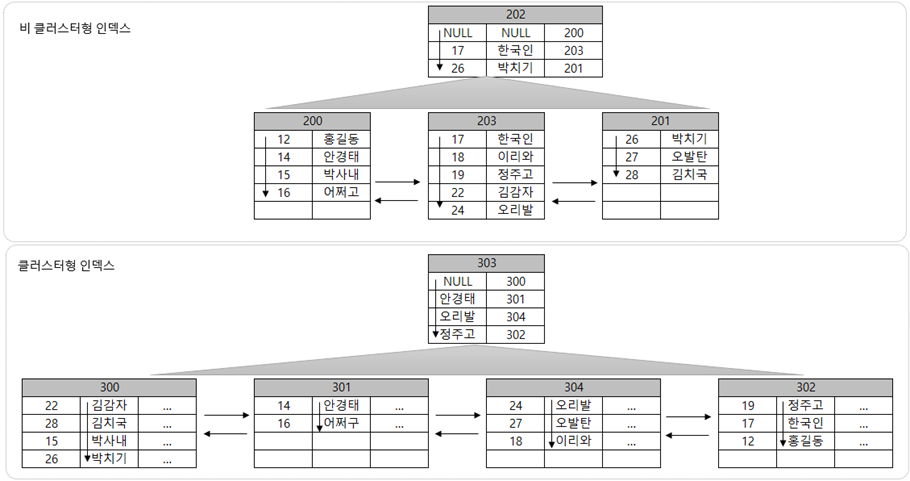
비클러스형 인덱스는 RID를 포기하고 클러스트형 인덱스의 키값을 가진다. 그 이유는 데이터가 다른 페이지로 옮겨짐에 따라 RID값이 변경되어 저장되어야 하는 부담을 덜기 위해서이다.
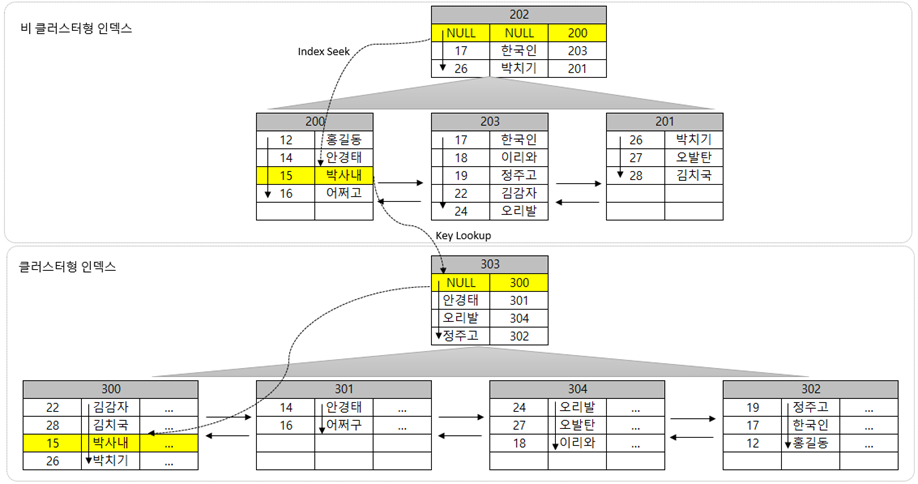
"15 박사내"를 찾기 위해 번호 컬럼의 "15" 값으로 조회한다고 가정하면, 번호컬럼으로 만들어진 비클러스터형 인덱스를 먼저 이용하여 검색을 합니다. "15" 값을 가지고 Root 페이지인 202 페이지에서 비교해서 200페이지를 찾습니다. 200페이지로 이동한 후 "15" 값을 가지고 데이터를 찾아 "15 박사내"를 찾습니다. 여기에서 번호와 이름만을 찾는다면 여기에서 종료가 되지만, 나머지 컬럼을 모두 알고 싶다면 다시 "박사내" 즉, 클러스터형인덱스의 키 컬럼을 가지고 클러스터형인덱스을 사용하게 됩니다. 303 페이지에서 "박사내"로 검색한 결과 300페이지를 찾고 300페이지로 이동하여 "박사내"와 일치하는 데이터를 찾습니다. "15 박사내"를 찾았고 나머지 컬럼의 정보들은 이 페이지에 모두 존재하게 됩니다.
페이지 분할 ( Page Split )
인덱스 페이지가 꽉 차게 되면 페이지 분할이 이루어집니다. 페이지 분할을 방지하기 위해서는 인덱스를 만들 때 인덱스 페이지를 어느 정도 비워 두도록 옵션을 사용해야 합니다.
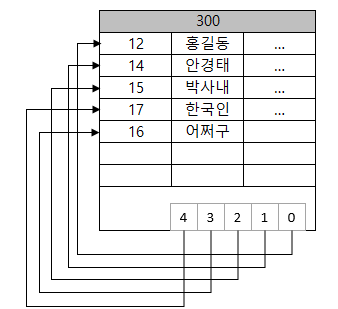
클러스트형 인덱스는 데이터 페이지와 데이터 페이지 안의 행이 정렬되어 있습니다. 이 정렬은 물리적인 정렬이 아닌 논리적인 정렬입니다.
디비로 누리는 특별한 세상 SQL Server 개발편
'개발 > 인덱스와 통계' 카테고리의 다른 글
| 인덱스에 포함된 열 조회 (0) | 2021.06.30 |
|---|---|
| Gathering SQL Server indexes statistics and usage information (0) | 2021.02.18 |
| 인덱스 생성 시 메모리 부족 (0) | 2020.12.22 |

